
The Google cloud platform outage began at 11:45pm and ended at 15:40pm PT, with impacts on the user-level and macro network detected by network monitoring company ThousandEyes at 12pm to 12:15pm.
There have been many reports of Google-owned services being unavailable and causing disruption.
Third-party apps that use Google Cloud space for hosting were also affected, including gamer voice chat platform Discord, picture messenger Snapchat and even Apple’s iCloud services.
The outage reportedly affected Canadian e-commerce company Shopify, causing one business owner thousands of dollars' worth of lost business, according to an email sent to the media site Mashable.
Reports from users of Google Nest’s products, which are from Google’s smart home company, claimed that thermostats, smart locks and cameras stopped working during the outage.
So we finally get AC, right? Great. Google is down. We have a Nest thermostat. Nest runs on Google. Can’t turn on AC because app is down. Neat. — Danny (@jDantastic) June 2, 2019
@googlenest It’s very inconvenient when the system is down. Especially if you use Nest Cameras for baby monitors. Is the outage expected to end soon? Sometimes I wish I just got simple baby monitors instead of paying a premium price and a monthly fee for an inconsistent service. — Chris Weix (@thebigwax) June 2, 2019
Google first made an incident status on its cloud outage at 12:25pm, reporting that it was “investigating an issue with the Google Compute Engine”, which was followed by another post at 12:59pm stating that the issue was related to “a larger network issue”.
At 13:36pm, Google stated: “We are experiencing high levels of network congestion in the eastern USA, affecting multiple service in Google Cloud, GSuite and YouTube.
“Users may see slow performance or intermittent errors. We believe we have identified the root cause of the congestion and expect to a return to normal service shortly.”
Google’s engineers completed the first of two phases of migration to correct the issues by nearly 3pm. A status at 17:09pm reported that the issue had been resolved for all affected users as of 4pm.
In a blog post on June 3, Benjamin Treynor Sloss, Google’s VP of Engineering, apologised.
Speaking on behalf of his department, Sloss said: “When we fall short of that goal—as we did yesterday—we take it very seriously.”
He explained the incident, detection and response of Google's engineering team, but also revealed the impacts of the outage and the next steps that the department would take to mitigate such issues in the future.
Overall, YouTube measured a 2.5% drop of views for one hour, while Google Cloud Storage measured a 30% reduction in traffic.
Approximately 1% of active Gmail users had problems with their account, which represents millions of users who couldn’t receive or send emails.
Low-bandwidth services like Google Search recorded only a short-lived increase in latency as they switched to serving from unaffected regions, then returned to normal.
Sloss added: “With all services restored to normal operation, Google’s engineering teams are now conducting a thorough post-mortem to ensure we understand all the contributing factors to both the network capacity loss and the slow restoration.
“We will then have a focused engineering sprint to ensure we have not only fixed the direct cause of the problem, but also guarded against the entire class of issues illustrated by this event.”
ThousandEyes released a graph (below) showing the disruption to content hosted in a GCE instance in GCP us-east4-c, but served dynamically via a CDN edge network, at 12pm.
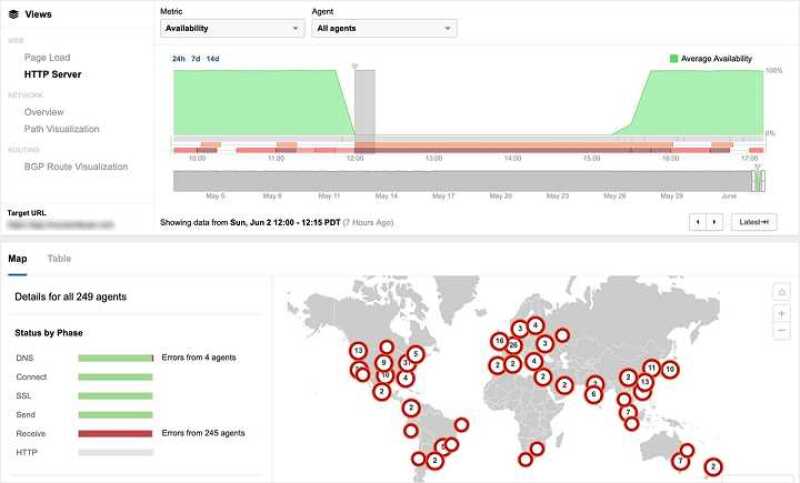
Users accessing other GCP-hosted services would have started to feel the impact of the outage at this time.
In a report on the outage, ThousandEye’s director, product marketing, Angelique Medina said: “One of the most important takeaways from cloud outages is that it’s vitally important to ensure your cloud architecture has sufficient resiliency measures, whether on a multi-region basis or even multi-cloud basis, to protect from future recurrence of outages. After all, it’s only reasonable to expect that IT infrastructure and services will sometimes have outages, even in the cloud.
“The cloud and the Internet are inherently prone to unpredictability because they are massive, complex and endlessly interconnected. The cloud is arguably still the best way to do IT for most businesses today, but it carries risks that no team should be unprepared for.
“Given the increasing complexity and diversity of the infrastructure, software and networks you rely on to run your business, you need timely visibility so you can tell what’s going on and get resolution as fast as possible.”
ThousandEyes recently reported thatChina Telecom’s backbone had suffered an outage.



